https://www.acmicpc.net/problem/15649
15649번: N과 M (1)
한 줄에 하나씩 문제의 조건을 만족하는 수열을 출력한다. 중복되는 수열을 여러 번 출력하면 안되며, 각 수열은 공백으로 구분해서 출력해야 한다. 수열은 사전 순으로 증가하는 순서로 출력해
www.acmicpc.net
백트래킹을 연습해보고 싶어서 고른 문제이다. 쉬운듯 어려운듯..
💡문제 분석 요약
자연수 N과 M이 있을 때, 1에서 N까지 길이가 M인 수열을 출력한다. 한 수열에 중복되는 수가 있으면 안된다.
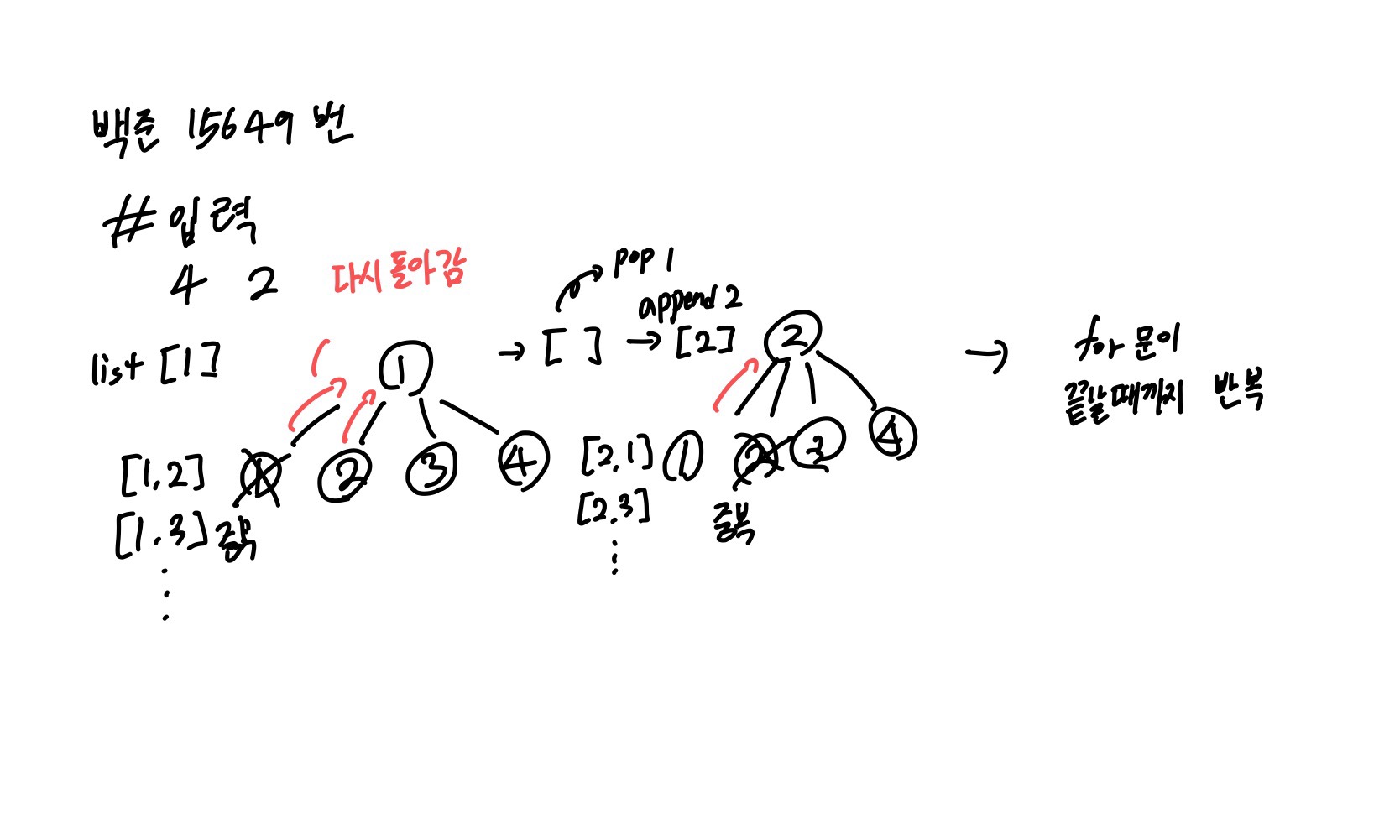
💡알고리즘 설계
1. search 함수에서, 1에서 N까지 숫자를 하나씩 list에 추가하고 함수를 다시 호출한다.
2. list의 길이가 M+1과 같다면 수열을 프린트하고 리턴한다.
3. list의 제일 마지막에 추가된 숫자를 pop하고, 다음 숫자를 list에 추가하고 함수를 호출한다.
💡코드
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
answer=[]
def search(count):
if count == M+1:
print(' '.join(map(str,answer)))
return
for i in range(1, N+1):
if i not in answer:
answer.append(i)
search(count+1)
answer.pop()
search(1)
count는 수열의 길이를 저장하기 위해 사용했다. len(count)를 활용해도 된다.
💡시간복잡도
첫번째 숫자를 선택하고 함수를 호출하는데 N이 걸리고, 이전에 사용했던 숫자를 제외하여 선택한 후 다시 함수를 호출하는데느 N-1이 걸린다. 따라서 (N)*(N-1)*(N-2)...*1 이므로 시간복잡도는 O(N!)이다/
💡 느낀점 or 기억할 정보
중복처리는 if i not in answer로 처리했다. c++를 쓸 때는 인덱스로 배열에 하나씩 접근해서 비교해야했는데 파이썬은 사람 말 같은 코드로 직관적으로 처리되는 점이 좋은 것 같다. 그러나 not in ~을 쓰면 배열을 하나씩 읽어서 시간이 O(N)씩 걸리기 때문에, 중복을 처리하는 배열 visited를 따로 만들어 관리하는 것이 시간 측면에서는 좋을 것 같다.
'알고리즘 문제 풀이' 카테고리의 다른 글
| [백준 16967] 배열 복원하기 - 파이썬 (0) | 2024.02.10 |
|---|---|
| [백준 11724] 연결 요소의 개수 - 파이썬 (0) | 2024.02.10 |
| [백준 11478번] 서로 다른 부분 문자열의 개수 - 파이썬 (0) | 2024.02.03 |
| [백준 10816번] 숫자 카드2 - 파이썬 (1) | 2024.02.03 |
| [백준 1697번] 숨바꼭질 - 파이썬 (2) | 2024.01.27 |


